Est. Reading time:
10 min
Est. Reading time:
This blog is a shorter intro to Raft, designed for people new to Distributed systems. The source Raft annotated paper : here
Typically, fault-tolerant systems require multiple copies of the service running together. This in a technical term is called a Distributed system.
There are two modes these "Distributed systems" can work :
In the first case, despite being a distributed system (from here on out, I am going to call it dist sys), there still exists a single point of failure and bottleneck. Yes, the database in itself may be a dist sys, but that would be considered in the second case a separate system.
It is this second case that truly gives us internet-scale services and the resilience of computer systems we have come to expect in this day and age. But accepting a single value across these multiple copies of the code, is surprisingly a very hard problem to solve. This is what consensus as a concept is.
To agree on a single value on multiple computers spread across a network, with all its faults and slow-downs is what consensus tries to do.
So far, the world has been dominated by Paxos as the de-facto standard for consensus algorithms. But it has its shortcomings :
This paper introduces Raft, simpler consensus algorithms. One designed with implementation and understandablity in mind.
Raft does this by employing some novel ideas such as:
Safety: A system ensures that at any given point a system cannot be left in a "bad"/"inconsistent" state.
State space refers to the ways the servers can be inconsistent
Consensus algorithms for practical systems usually have the following properties :
non-Byzantine: scenarios where nodes are assumed to be reliable and will not act maliciously or deceptively
Things get very interesting when we have consistent timings, we can simply attach a timestamp to each request and order the logs based on this time. Solves all our consistency problems. But the real world sadly, is full of slow-downs and inconsistent times.
Raft is similar to algorithms such as "Viewstamped Replication", but has its own features such as :
Liveliness: Something good eventually happens, the system can never be in a stuck state.
This paper goes in the following order :
We will also follow a similar structure to this post.
State machines are simple machines, when given a start state and a bunch of inputs, the resulting state is always the same and known. This is often used in dist sys.
Systems like GFS, and HDFS use a separate Replicated State machine to manage leader election and store metadata of the system (AKA Zookeeper).
Replicated state machines are implemented using a replicated log. This is simply a log of all the inputs thus far. The problem just went from having a consistent state machine across all systems to having a consistent and replicated log.
Replicated log: A series of commands. A consistent replicated log has all the commands in the same
order.
Keeping this replicated log consistent is the job of the consensus algorithms. From there the replicated log can be applied to the state machine to get consistent states across the system.
melds all of them together.
peer-to-peer system with a weak leader, in trade for better performance, this makes things hard for real-world systems.Do we really need more reasons than the first one?
In raft, new log entries, always flow from the leader to the followers. Reads can come from any of the followers. Given this leader approach, Raft decomposes the algorithm in the following :
Leader is always any one of the nodes in the system.
Phew...that was an intense paragraph before this. Most of it probably did not make sense, and that is fine. Cus I haven't been introduced to the actors in this algorithm.
In a given system, all nodes start off as followers. Every node has a randomised timer. When this timer goes off, the follower becomes a candidate and sends a RequestVote call to every node in the system.
Every time a follower becomes a candidate, it increments its term by one. It sends this term in every RequestVote call. Response from the nodes can either be true (when it is voting in favour) or false (against). Along with this, every node sends back its state no matter the voting status.
Now comes a critical part of Raft : If a candidate or leader sees a term greater than its own, it reverts instantly to follower and updates its term. Every time a follower votes in favour of a candidate, it updates its term to the candidate's term.
Raft uses a heartbeat mechanism to trigger a leader election. On every heartbeat from the leader to the follower, the timer gets reset, when there aren't any heartbeats for a said time when the timer runs out, an election is triggered.
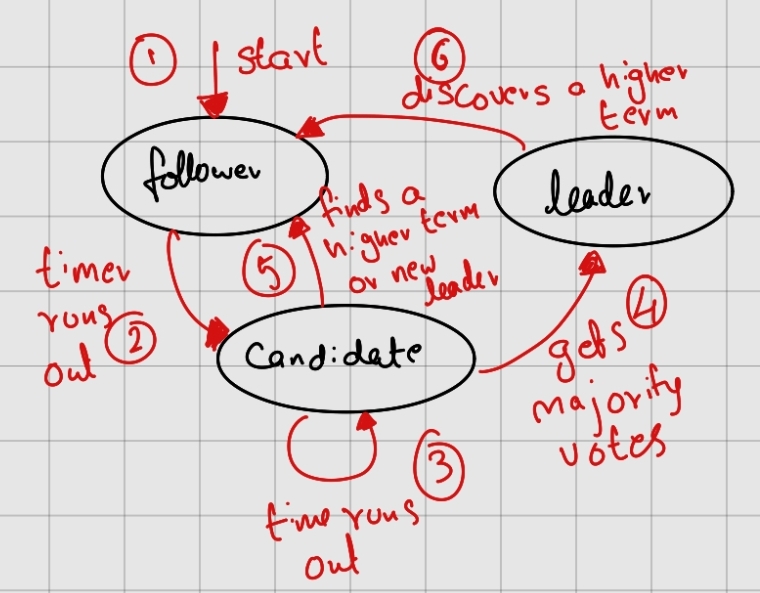
When a follower's timer runs out, the following happens :
When a candidate's timer runs out, it retries the sending RequestVote requests.
From here, there can be three cases :
Each server can vote to at most a single server. And this combined with majority rule ensures not more than 1 leader can be elected. Votes are given on a first come first serve basis.
Case 1: When a candidate wins the election, it sends a heartbeat message to all the servers.
Every node in the system knows the number of nodes in the system. This is the only way that a candidate will be able to determine if it has a majority. Raft does support membership changes, but thats not something I cover in this post.
Case 2: While waiting for votes, if the candidate receives an AppendEntries request claiming to be a leader if the "claimed" leader's term is greater than or equal to the current candidate's term, it reverts to a follower state and updates its term and its log.
If the "claimed" leader's term is smaller than the candidates, it continues being a candidate.
Case 3: When none of the candidates receives a majority vote, the timer simply runs out and the election restarts. Without measures, this can go on indefinitely. Hence, one of the measures taken is to always have an odd number of nodes in the system.
So, when does a server vote for a candidates request :
The RequestVote request has details about the candidate's log, it contains the latest index and its term. A node will vote in favour of a candidate only if the index and the term of the last entry are greater than or equal to its own. If both the logs have the same term, then the longer log is the latest one.
In short, a vote in favour of the candidate is given only if its log is at least as up-to-date as that of the follower. Combine this with the majority vote, the leader must have the log of the more recently committed (as committed entries are present in a majority of the nodes) to get a majority. I call this a
two-way majorityrule!
When a write request shows up, the leader, it parallelly sends AppendEntries request to all the nodes in the system. In case of a slow or failed node, this AppendEntries request is retried indefinitely (Even after the leader has responded back to the client).
The leader decides when it's safe to apply an entry to the state machines. This state is called committed. When the AppendEntries Request has successfully replicated the entries in the majority of the logs in the system, the entry is considered to be committed. The leader includes this committed status in the upcoming, AppendEntries request. When the follower learns that a given entry is committed, it goes ahead and applies it to the state machine.
This way of Log matching ensures two critical properties in the Raft log system :
The first one happens because the leader creates at most one entry with a given log index (Once again attributed to the fact that majority voting of consistent states is required to become a leader)
If the follower does not find an entry in its log with the given term and index, it refuses the AppendEntries request. As an example, let's take the following case:
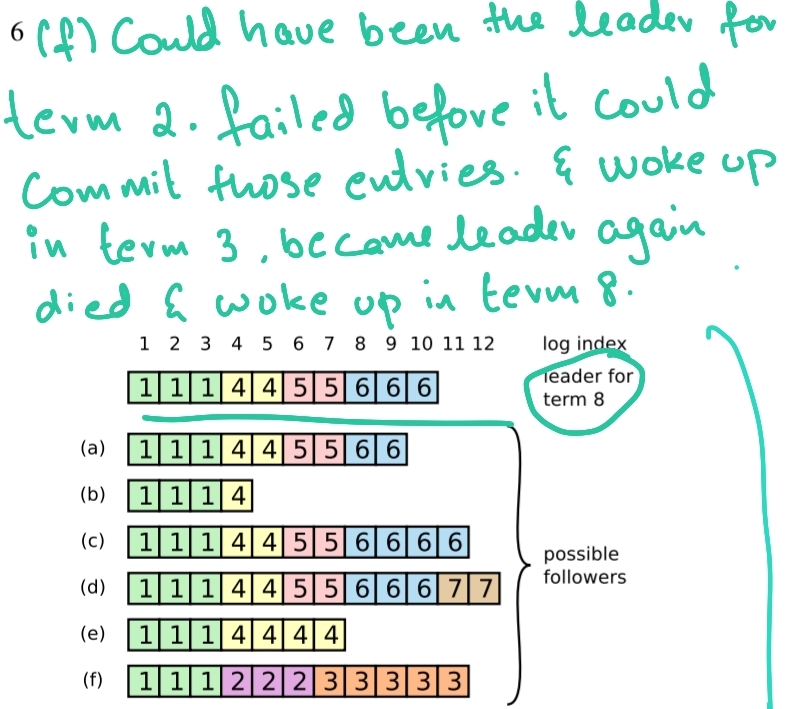
In the above case, we see that some node is the leader in term 8. We also see that node "f" has some entries in terms 2 and 3. These don't seem to appear is any of the other nodes, leading us to believe that those entries were never successfully committed.
If they were, then the current leader couldn't have gotten its majority with its current log. So how does Raft handle this very old and outdated follower?
Conflicting entries like these are overwritten by the leader with entries from the leaders logs. This is considered safe, as we look for a majority while electing this leader with immense power and majority while committing.
These consistency checks are part of the AppendEntries Request, where the leader maintains a nextIndex for each follower. Which is the next log entry index the leader will try sending to the follower. (This reminds me of a pushback trial method). In case the said nextIndex is inconsistent, the nextIndex reduces by 1.
And as stated before, a leader can never overwrite of delete its own logs.
Now, is is possible that the entry was replicated to the majority of the logs, but the leader failed right before it could indicate to all followers that the entry is committed. The new leader will now have these majority replicated but un-committed entries in its log. But a leader will NEVER try and commit log entries by counting replicas from previous terms. It will do so only for the current term. But if an entry from the current term is committed, then all prior entries are also considered committed and applied to the state machine. This is the Log matching property coming to the rescue.
Raft promises that if a log entry is committed in a given term, then that entry will be present in leaders of all higher-numbered terms. This is called the Leader Completeness property. Let's assume this property is false, we need to prove a contradiction now :
Suppose a leader from term T leaderT commits a log entry in its term, and say this entry is not stored by leader for some future term U where the leader is leaderU.
This way, we know that the Leader Completeness property is held true, eventually helping prove the correctness of the algorithm itself. Raft TLA+ Specs are written along the same lines, and a working model of this exists for testing.
As a final note to this post, let's look into the randomized timer that Raft employs. I think it's an understood fact that without a steady leader, the system cannot make progress. With randomized timers being very small, there is a possibility that leaders are constantly changing and no progress is made. For this reason, there is a requirement for this timeout :
broadcastTime << electionTimeout << MTBF
MTBF - Mean time between failures
With that, I hope you learnt something about consensus and raft through this post. Adios.
Annotated raft paper : Raft annotated paper