Est. Reading time:
6 min
Est. Reading time:
This blog was written for a presentation on Basic of Consensus
In the age of internet scale service, we inherently expect services to be always present, 100% accurate and instantaneous. Or in verbs :
For a successful system, reality must take precedence over public relations. - Richard Feynman
And nature does everything in its power to make sure the above properties don't hold true.
Hardware fails, People live far from your servers, Load is unpredictable, Network is unreliable.
Requirements :
So, maybe...Throw costly hardware at the problem?
Hardware cost don't scale linearly with the spec of hardware. And this still doesn't solve the problem. - Hardware can still fail - This costly hardware and be far from your user
Multiple computers but one storage...Shared DB architecture?
A good start! But there still only exists one copy of the data. If that fails, your system is down. Sounds enticing, as its easy to build such systems, helps with scale and latency. But we are one data stores failure away from being unavailable.

So maybe make multiple copies of the data on different systems?
Ah! You just described a distributed system. - This would be the perfect solution, but this isn't as simple as it seems. Even here, we can have two, but both have a distributed system in them :


Turns out, enemies of distributed systems are a subset of internet scale systems. We just moved the problem to a different layer.
Funnily enough, given more replicas in the system, higher probability of failure of a given system.
Most of problem with replication lies in the changes to data. We need to make sure the system as a whole is consistent and these replicas agree with each other when a value is read. - This is Consensus.

Let's assume an online storePotatoZon uses a distributed system to handle traffic.

a adds a potato to the cart (Lets say this request went to Server Q).Q).Z).Luckily, both
QandZreplicas were up-to date and consistent.
Z).Say, right after the request to remove the Ferrari, server
Zcrashes but not before replicating to serverX. As PotatoZon uses asynchronous replication, even though the changes were not seen by serverQthe user got confirmation for his Ferrari removal.
Q).Oh no...he sees that both Ferrari and the potato are ordered. A costly mistake.
Remember, server Q did not see the change of removal of the Ferrari from cart, but handled the checkout.
Asynchronous replication : application developers can build on “weakly” consistent storage models that do not use coordination; in this case developers must reason about consistency at the application level
You might say: Navin, let's just use synchronous replication and wait for all replicas to acknowledge the writes. In which case, the checkout would have not even happened as server Q crashed.
 (I'm sorry for the tiny size, atleast it's a SVG, so feel free to zoom)
(I'm sorry for the tiny size, atleast it's a SVG, so feel free to zoom)
Strong consistency can be enforced in a general-purpose way at the storage or memory layer via classical distributed coordination (consensus, transactions, etc.),
but this is often unattractive for latency and availability reasons.
It's a shame that we can't even have be resiliant to one failure if we have to correct
Now if your seasoned with distributed systems, you might propose this solution :
This way, it seems like we maintain consistency and availability. But this is not the case. Right?
Let's again take the same example of PotatoZon. Three server Q, Z and X. And eventually server Z seems like dead to Q and X.
But what if the network between the nodes were partitioned? So Z is still alive and can accept requests, but Q and X can't reach it and vice versa. So in this case :
Z would assume Q and X are deadYikes! So messy. This is called Split brain issue.
GitHub actually had a split brain issue in 2018, leading to downtime and messy data.
Really interesting stuff : https://www.youtube.com/watch?v=dsHyUgGMht0&ab_channel=KevinFang
So how is this problem solved in real life? Introducing Consensus algorithms. There are many Consensus algorithms with different gaurentees and properties. But two widely used ones are Paxos and Raft. We'll look at what Raft does in a very high level.
We do not have the time to see Raft in detail, but if interested : here
Raft operate with a leader-follower model. But a weak leader to be able to handle leader failures.
Raft operates on a state machine model, where each replica holds the log of writes, like this :
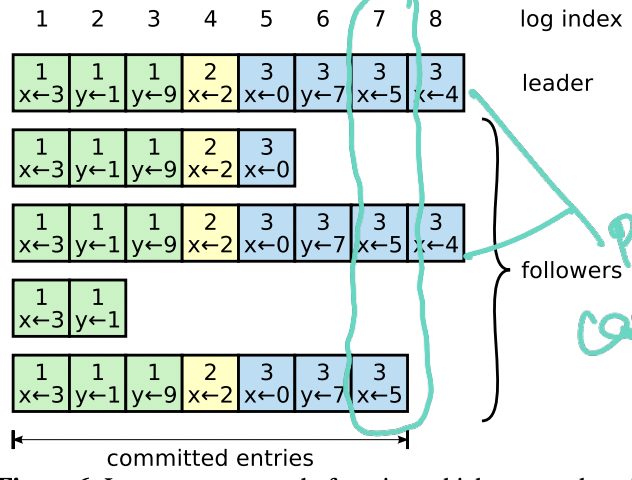
The number on top of each entry is a term number. Every write will be associated with a term number.
There exists heart beats between followers and leader, and each follower has a randomized timeout. If it doesn't receive a heartbeat in that time, it will become a candidate to try and become a leader.
A follower becomes a candidate when its timer run out
Each follower's random timer is reset when it receives heart beat from the leader
A leader is selected using a voting system
So this seem like the leader must have all the membership data to know what the majority is. Raft has some algorithm to hand this as well. We will not go into this.
Writes only go to the leader
A write is considered committed when it is replicated to a majority of the followers
If the leader observes a given follower is behind, it sends its data for the follower to catch up. (This is actually safe as the leader could have become one, ONLY if it had all the committed writes)
Reads can go to any follower.
This plays well into our issues, where majority writes make sure that even if some nodes are down, we can still go through writes.
Reads can come from any replica, so we can have low latency reads.
Raft has a two-way majority :
A given write cannot be committed unless its replicated to a majority of the nodes
A leader cannot be elected unless it has a majority of votes
This means a given leader can become a leader ONLY if it has the latest committed write. Making sure we are always consistent!
Some really shrewd eyed amongst you might say,
What if there were 6 nodes, and one candidate got vote from 2 of them and another candidate from another two. Where the connection between these three have been cut off.
Well, there exists a simple solution to this. Make sure that number of nodes in your cluster is always odd.
Really, the solution to that is that simple xD
And if more than majority of the nodes are down, the system becomes read-only and none of the writes pass through. Which is an acceptable trade-off in worst case situations.
Consensus is a fundamental building block of distributed systems. It allows us to build reliable, available, and scalable systems that can handle failures gracefully. In this presentation, we saw majorly the issues that consensus solves for us and on a very high level how Raft works.
Adios.